Der menschengemachte Klimawandel: Ursachen, Effekte und Lösungswege















Kurs: Der menschengemachte Klimawandel: Ursachen, Effekte und Lösungswege | OnCourse UB
-
-
Nachhaltigkeit von Künstlicher Intelligenz
Um die Nachhaltigkeit von Künstlicher Intelligenz zu ermöglichen, muss sichergestellt werden, dass die Entwicklung, Implementierung und Nutzung von KI-Technologien ethisch, umweltverträglich und sozial verantwortlich erfolgt. Dies beinhaltet die Berücksichtigung von Umweltauswirkungen bei der Herstellung von Hardware, den ressourcenschonenden Betrieb von KI-Systemen, die Einhaltung ethischer Grundsätze in der Datennutzung, den Schutz der Privatsphäre und den Ausschluss von Diskriminierung. Durch die nachhaltige Gestaltung von KI-Systemen werden die Erreichung positiver Auswirkungen auf Gesellschaft und Umwelt angestrebt, während negative Folgen minimiert werden sollen. Dies umfasst auch die Förderung von Forschung und Entwicklung, die auf Langfristigkeit und Verantwortung ausgerichtet ist.
Beim Einsatz von KI sollten Effizienz und Suffizienz beachtet werden.
Effiziente KI
Effiziente KI nutzt Ressourcen, Rechenzeit und Speicherplatz sparsam, um das vorliegende Problem zu lösen. Bei suffizienten KI-Lösungen wird bereits auf bestehende Hardware, Modelle und/oder Trainingsdaten aufgebaut. Im Gegensatz zur Effizienz werden bei Suffizienz keine Rebound-Effekte erwartet.
(Boll et. al, 2022; Beesch et. al, 2023).
 Die Hardware ist die physische Infrastruktur, auf der
KI-Systeme trainiert und als Modelle angewendet werden. Dabei kann es sich um
Cloud-Rechenzentren oder mobile Endgeräte handeln. In beiden Fällen bilden eine
lange Nutzungsdauer, Reparierbarkeit und eine ökologisch vertretbare
Herstellung die Grundlage für eine nachhaltige KI, da dadurch Ressourcen
gespart werden. Zudem ist eine zirkuläre, möglichst rückstandsfreie
Wertschöpfungskette zentral - die Recyclingquote muss erhöht und die
Rückgewinnung von Materialien verstärkt werden.
Die Hardware ist die physische Infrastruktur, auf der
KI-Systeme trainiert und als Modelle angewendet werden. Dabei kann es sich um
Cloud-Rechenzentren oder mobile Endgeräte handeln. In beiden Fällen bilden eine
lange Nutzungsdauer, Reparierbarkeit und eine ökologisch vertretbare
Herstellung die Grundlage für eine nachhaltige KI, da dadurch Ressourcen
gespart werden. Zudem ist eine zirkuläre, möglichst rückstandsfreie
Wertschöpfungskette zentral - die Recyclingquote muss erhöht und die
Rückgewinnung von Materialien verstärkt werden.  Die Datenmenge ist entscheidend für die Genauigkeit des
resultierenden Modells. Große Datenmengen treiben aber auch den
Energieverbrauch in die Höhe. Energieverbrauch und Genauigkeit stehen zudem in
einem ungesunden Verhältnis: Für weniger als ein halbes Prozent mehr
Genauigkeit ist das Zehnfache an Energie nötig. Suffizienz bedeutet hier, von
vornherein zu überlegen, welche Genauigkeit für die Anwendung erforderlich ist und die Datenmenge für das Training entsprechend anzupassen.
Die Datenmenge ist entscheidend für die Genauigkeit des
resultierenden Modells. Große Datenmengen treiben aber auch den
Energieverbrauch in die Höhe. Energieverbrauch und Genauigkeit stehen zudem in
einem ungesunden Verhältnis: Für weniger als ein halbes Prozent mehr
Genauigkeit ist das Zehnfache an Energie nötig. Suffizienz bedeutet hier, von
vornherein zu überlegen, welche Genauigkeit für die Anwendung erforderlich ist und die Datenmenge für das Training entsprechend anzupassen.  Auch die
Wiederverwendung bestehender KI-Algorithmen für ähnliche Anwendungen kann
Ressourcen sparen, da die energieintensive Trainingsphase entfallen oder
verkürzt werden kann. Voraussetzung dafür ist die öffentliche Verfügbarkeit des
Quellcodes und der trainierten Modelle (Open Source). Dadurch kann die
Codebasis des Programms eingesehen, verändert und wiederverwendet werden.
Auch die
Wiederverwendung bestehender KI-Algorithmen für ähnliche Anwendungen kann
Ressourcen sparen, da die energieintensive Trainingsphase entfallen oder
verkürzt werden kann. Voraussetzung dafür ist die öffentliche Verfügbarkeit des
Quellcodes und der trainierten Modelle (Open Source). Dadurch kann die
Codebasis des Programms eingesehen, verändert und wiederverwendet werden.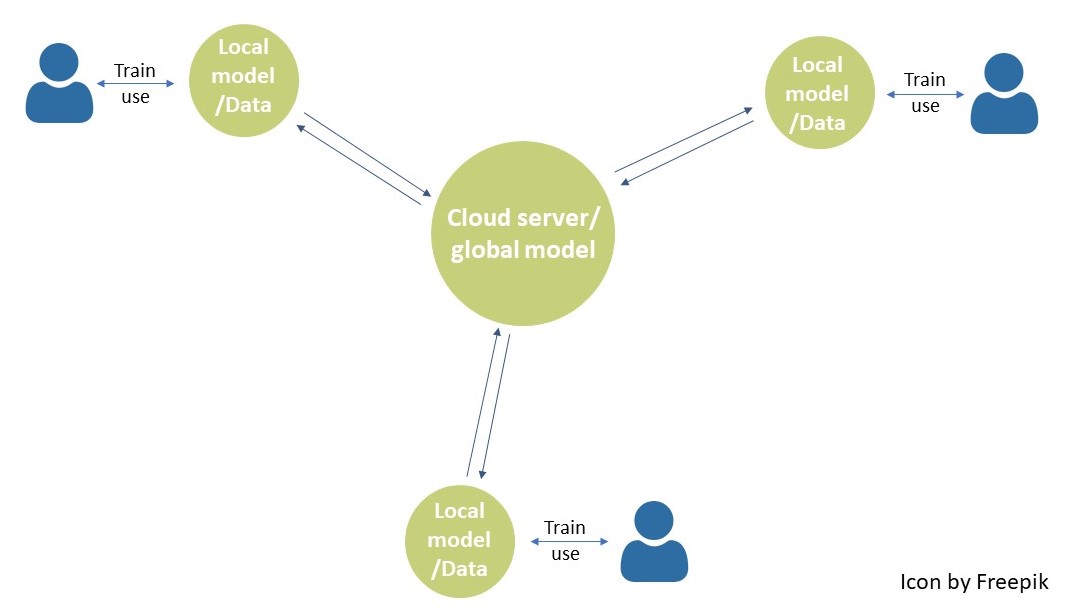 In diesem
Zusammenhang ist auch der Ansatz des federated learning (kollaboratives/föderiertes
Lernen) zu nennen. Dabei lernen verschiedene Maschinen voneinander, indem sie
trainierte Modelle gemeinsam nutzen. Dieses Prinzip wird beispielsweise für die
Autovervollständigungsfunktion der Texteingabe genutzt: Diese lernt durch ihre
Anwender*innen, bessere Vorschläge zu machen. Die entstandenen
Modellanpassungen werden an die Smartphonehersteller:innen und somit an andere
Telefone weitergeleitet. Das erhöht die Genauigkeit der Systeme, ohne dass
energieintensive Trainings wiederholt werden müssen.
In diesem
Zusammenhang ist auch der Ansatz des federated learning (kollaboratives/föderiertes
Lernen) zu nennen. Dabei lernen verschiedene Maschinen voneinander, indem sie
trainierte Modelle gemeinsam nutzen. Dieses Prinzip wird beispielsweise für die
Autovervollständigungsfunktion der Texteingabe genutzt: Diese lernt durch ihre
Anwender*innen, bessere Vorschläge zu machen. Die entstandenen
Modellanpassungen werden an die Smartphonehersteller:innen und somit an andere
Telefone weitergeleitet. Das erhöht die Genauigkeit der Systeme, ohne dass
energieintensive Trainings wiederholt werden müssen. KI-basierte
Angebote können auch energiesparender sein, indem sie nicht konstant im
Hintergrund laufen, sondern nur durch bestimmte Auslöser aktiviert werden.
Beispielsweise vergleichen Sprachsysteme wie Alexa nicht unentwegt das
Gesprochene mit dem gesamten Sprachdatensatz, sondern warten auf den
Aktivierungsbefehl (Wake-word-detection). Auch der Einsatz mehrstufiger
Prozesse kann Energie sparen. So wird bei der Produktsuche auf Online-Plattformen
stark mit energieeffizienten Filtern gearbeitet, die Hunderttausende von
Suchergebnissen auf Tausende oder wenige Hundert reduzieren.
KI-basierte
Angebote können auch energiesparender sein, indem sie nicht konstant im
Hintergrund laufen, sondern nur durch bestimmte Auslöser aktiviert werden.
Beispielsweise vergleichen Sprachsysteme wie Alexa nicht unentwegt das
Gesprochene mit dem gesamten Sprachdatensatz, sondern warten auf den
Aktivierungsbefehl (Wake-word-detection). Auch der Einsatz mehrstufiger
Prozesse kann Energie sparen. So wird bei der Produktsuche auf Online-Plattformen
stark mit energieeffizienten Filtern gearbeitet, die Hunderttausende von
Suchergebnissen auf Tausende oder wenige Hundert reduzieren. -